

Neben Politik und Wirtschaft ist sicherlich die Wissenschaft das dritte große Seilschaften-Dorado.
…, so stand es unlängst in einem Essay zu lesen.
Da ist sicher was dran. Denn wo man hinsichtlich Begutachtungen, Berufungen, Fördermitteln, Evaluationen, Zitierungen et cetera derart von „Peers“ abhängig ist, da wird man wohl förmlich gedrängt zu Cliquenbildung, Gschaftlhuberei, Günstlingswirtschaft, … Und eine Ausprägung davon sind bisweilen Zitierkartelle.
Nehmen wir zunächst den aufrichtigen Wissenschaftler. Wenn er seine Resultate veröffentlicht, sieht er es als seine ehrenhafte Pflicht an, sämtliche relevanten Vorarbeiten zu zitieren. Auch solche von Personen, mit deren Inhalten er ansonsten nicht übereinstimmt – schließlich werden womöglich gerade dadurch fruchtbare Diskussionen befördert. Ordnungsgemäßes und gründliches Zitieren ist für ihn somit ein klares Qualitätsmerkmal seiner Forschungstätigkeit.
Doch so denken bei weitem nicht alle. Für andere sind Zitate vielmehr ein schnödes Mittel, das gewinnbringend für die eigene Karriere genutzt werden kann. Von daher zitieren sie ausschließlich die Arbeiten ihrer Freunde und Kollegen, die im Gegenzug wiederum sie selbst zitieren. Auf diese Weise entstehen Gruppen gleichgesinnter Kollegen, in denen jeder jeweils die Karrieren der anderen fördert – Zitierkartelle eben. Diesen Beitrag weiterlesen »
 Im Wall Street Journal erschien unlängst ein Artikel mit dem Titel
Im Wall Street Journal erschien unlängst ein Artikel mit dem Titel  „Wissenschaftsbetrug ist selten. Stimmt das eigentlich?“ Diese Frage stellte unser „Wissenschaftsnarr“ Anfang des Jahres in seiner Laborjournal-Kolumne (
„Wissenschaftsbetrug ist selten. Stimmt das eigentlich?“ Diese Frage stellte unser „Wissenschaftsnarr“ Anfang des Jahres in seiner Laborjournal-Kolumne ( Öfter schon haben wir über „Zombie-Paper“ gemeckert. Artikel also, die trotz erfolgter Retraction munter weiter zitiert werden. Beispielsweise
Öfter schon haben wir über „Zombie-Paper“ gemeckert. Artikel also, die trotz erfolgter Retraction munter weiter zitiert werden. Beispielsweise  Mehrfach haben wir schon darüber berichtet, auf welch dreiste Weise das System wissenschaftlichen Publizierens für betrügerische Aktivitäten missbraucht wird – zuletzt etwa
Mehrfach haben wir schon darüber berichtet, auf welch dreiste Weise das System wissenschaftlichen Publizierens für betrügerische Aktivitäten missbraucht wird – zuletzt etwa 
 Eine Retraktion Ihres neuesten Artikels wäre das Beste, das Ihnen passieren kann – zumindest hinsichtlich Ihres Bekanntheitsgrades. Diese Aussage macht keinen Sinn, finden Sie? Schließlich kann eine widerrufene Publikation nicht mehr zitiert werden – schon allein weil sie Fehler enthält? Weit gefehlt.
Eine Retraktion Ihres neuesten Artikels wäre das Beste, das Ihnen passieren kann – zumindest hinsichtlich Ihres Bekanntheitsgrades. Diese Aussage macht keinen Sinn, finden Sie? Schließlich kann eine widerrufene Publikation nicht mehr zitiert werden – schon allein weil sie Fehler enthält? Weit gefehlt.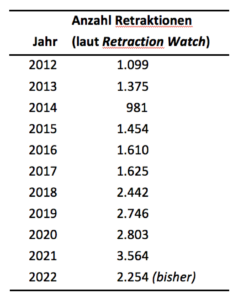 Zudem gibt es manchmal auch keine andere als die zurückgezogene Publikation, die zum Beispiel eine bestimmte Methode beschreibt. Überhaupt muss ja nicht alles an einem zurückgezogenen Artikel falsch sein.
Zudem gibt es manchmal auch keine andere als die zurückgezogene Publikation, die zum Beispiel eine bestimmte Methode beschreibt. Überhaupt muss ja nicht alles an einem zurückgezogenen Artikel falsch sein. __________________________
__________________________
 Ende letzter Woche erreichte uns eine
Ende letzter Woche erreichte uns eine 



