"Mehr Licht"
Nervige Replikationskrise
Von Victor Spoormaker, München
(12.07.2016) Viele Befunde aus den Neurowissenschaften scheinen schwer reproduzierbar. Die Gründe liegen meist in unzureichender Statistik, gepaart mit Forscher-Bias. Was könnte die gesamte medizinische Forschung aus dem Dilemma lernen?
Die Reproduzierbarkeit neurowissenschaftlicher Ergebnisse erwies sich zuletzt als derart gering, dass manche Forscher von einer Replikationskrise in den Neurowissenschaften sprechen. Obwohl Statistiker schon lange auf die Grenzen der Art und Weise hingewiesen haben, wie hier bis heute Signifikanztests (auch als Nullhypothese-Signifikanztests bezeichnet) durchgeführt werden. Doch erst der inzwischen berühmt-berüchtigte Artikel des Stanford-Professors John Ioannidis mit dem Titel „Warum die meisten veröffentlichten Forschungsergebnisse falsch sind“ verschaffte den Themen Reproduzierbarkeit und falsch positive Ergebnisse vor gut zehn Jahren erhöhte Aufmerksamkeit in der medizinischen und neurowissenschaftlichen Forschung.
Die experimentelle Evidenz aus systematischen Untersuchungen zu Reproduzierbarkeitsraten wächst seitdem dennoch nur langsam. Gleichwohl verheißen bereits die ersten, hierzu erhobenen Daten nichts Gutes. 2011 veröffentlichten etwa Forscher des Pharmariesen Bayer interne Studien zur Replikation präklinisch-experimenteller Ergebnisse aus der Onkologie, zu Herz-Kreislauf-Erkrankungen sowie zu Aspekten der Frauengesundheit. Die Autoren berichteten, dass sie die Ergebnisse von 21 Prozent aller Versuche voll reproduzieren konnten, bei weiteren 11 Prozent gelang dies wenigstens teilweise (2). In einer ähnlichen Analyse präklinischer Resultate aus der Onkologie kam die Firma Amgen gar auf eine Reproduzierbarkeitsrate von nur 11 Prozent (3). Es gibt noch keine empirischen Daten über präklinische Experimente in den Neurowissenschaften, aber eine Analyse legt nahe, dass die entsprechenden Ergebnisse ähnlich (oder gar schlechter) ausfallen.
Der generelle Schlüssel, um solide Resultate zu erhalten, ist, dass man die Probenzahl hoch genug wählt, um einen erwarteten Effekt bestimmter Größe zuverlässig erfassen zu können – man bezeichnet dies auch als statistische Power. Wenn große Effekte erwartet werden, reichen kleine Probenzahlen aus, um mit hinreichender Wahrscheinlichkeit den Effekt so zu detektieren, wie er auch für die Gesamtpopulation gilt – entsprechend sind für kleinere Effekte größere Proben erforderlich. Als hinreichende Wahrscheinlichkeit sieht man in der Regel 80 Prozent an (sie kann aber auch bei 70 oder 90 Prozent liegen) – was bedeutet, dass man die Probengröße für eine angepeilte Studie derart wählt, dass man damit einen Effekt bestimmter Größe mit 80-prozentiger Wahrscheinlichkeit detektiert. Wählt man eine kleinere Probenzahl, sinkt diese Chance. In einer Analyse von häufig in präklinisch-neurowissenschaftlichen Studien verwendeten Experimenten, deren Effektgrößen durch Meta-Analysen geschätzt wurden, stellte sich heraus, dass die mittlere statistische Power lediglich 18 bis 31 Prozent betrug (4). Das ist besorgniserregend, da es zeigt, dass die Stichprobengrößen oftmals viel zu niedrig waren. Wir müssen daher befürchten, dass in einigen Fällen echte Effekte von mäßiger Größe überhaupt nicht detektiert werden konnten – und stattdessen in anderen Fällen überschätzte falsch positive Ergebnisse als „wahr“ berichtet wurden.
Gerade bei letzterem – dem Entdecken falsch positiver Effekte – kommt noch das Thema „Bias“ dazu (1). Ein Beispiel dafür ist, dass zu viel Flexibilität in den Analysen steckt, über die man zudem oftmals auch nicht aufgeklärt wird. Das heißt, dass Forscher die erhaltenen Daten letztlich für andere Zielsetzungen und/oder auf eine andere Weise analysieren als ursprünglich geplant, bis sie irgendwo einen signifikanten Effekt finden. Ein weiteres Beispiel ist ein positiver Publikations-Bias innerhalb eines Felds. In den neurowissenschaftlichen Zeitschriften hat etwa die Veröffentlichung positiver Ergebnisse klaren Vorrang: rund 85 Prozent der Publikationen beschreiben positive Resultate, Null-Befunde sind die Ausnahme (5).
Wenn ein solcher Bias existiert, und das Feld zudem von vielen kleinen, „unterpowerten“ Studien getragen wird statt von solchen mit adäquater Power, dann führt dies unweigerlich zu einer relativ hohen Verbreitung von publizierten „Fehlalarmen“ – Falsch Positiven also. Und selbst wenn statistisch unterpowerte Studien einen echten Effekt detektieren, können sie leicht das Ausmaß des Effekts überschätzen, da es immer eine Zufallsvariabilität von Probe zu Probe gibt – gerade bei kleinen Stichproben (6). Einige Proben werden daher einen Effekt zeigen, der unter dem wahren Effekt liegt, haben damit eine geringere Wahrscheinlichkeit für signifikante p-Werte – und werden eher nicht (mit)veröffentlicht; andere werden einen Effekt über dem wahren Effekt und dadurch eher signifikante p-Werte zeigen – und natürlich veröffentlicht werden. Dies führt schließlich dazu, dass die geschätzten Effektgrößen in Meta-Analysen oftmals künstlich aufgeblasen werden und stattdessen „in Wahrheit“ viel kleiner sein könnten – was wiederum bedeutet, dass die statistische Power häufig noch niedriger sein könnte als die ohnehin schon niedrige beobachtete Power (4).
Die beiden Berichte von Bayer und Amgen liefern zwar Werte für die Größe dieses „dunklen Problems“, gehen aber nicht auf die Gründe ein, warum die meisten Experimente nicht repliziert werden konnten. Mehr zu diesem Aspekt bietet eine kürzlich veröffentlichte großangelegte Replikationsstudie (7) von der Open Science Collaboration, in der mehrere Teams hundert kognitiv-psychologische und sozialpsychologische Studien aus dem Jahr 2008 wiederholten. Die Replikations-Teams holten dazu Originalmaterialien von den Autoren der Erststudien ein, veröffentlichten ihre Studienprotokolle vor deren Durchführung und stellten sicher, dass ihre Replikationsexperimente hohe statistische Power hatten (Gesamtpower von 92 Prozent im Mittel). Die Reproduzierbarkeit prüften sie auf mehrfache Weise – etwa ob wieder entsprechende Signifikanz erhalten wurde, ob der ursprüngliche Effekt in den 95%-Zufallsfehlerbereich des Replikationsergebnisses fiel, oder ob die Autoren seinerzeit subjektiv über die Replikation ihrer experimentellen Befunde berichteten.
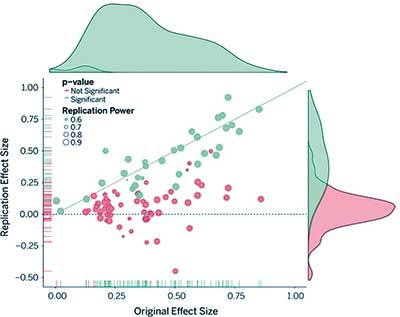
Die erste wichtige Erkenntnis dieser Replikationsstudie war, dass die erhaltenen Effektgrößen im Allgemeinen etwa nur halb so groß waren wie diejenigen der exakt gleichen Originalstudien (Bild 1). Der Anteil der positiven Effekte mit signifikanten Ergebnissen betrug 97 Prozent in den ursprünglichen Studien, doch nur 36 Prozent in den replizierten Studien. Etwa die Hälfte der ursprünglichen Effekte fiel in den 95%-Zufallsfehlerbereich der Ergebnisse aus den entsprechenden Replikationen; 39 Prozent der Studien wurden subjektiv als „repliziert“ berichtet. Insgesamt waren die Zahlen für die kognitiv-psychologischen Studien besser als für die sozialpsychologischen: rund 50 Prozent der ersteren hatten einen signifikanten p-Wert in der Replikation, dagegen nur 25 Prozent der letzteren. Interessanterweise variierten die p-Werte der nicht-replizierten Studien sehr stark, zudem war die Verteilung der nicht-reproduzierten Effektgrößen nahezu um Null zentriert.
Diese groß angelegte Replikationsstudie erfasste zudem noch weitere Charakteristika der Original- und Replikationsarbeiten, unter anderem etwa die Bedeutung des jeweiligen Ergebnisses (unter anderem in Form von Zitierungen), die „Unerwartetheit“ des Ergebnisses, Erfahrung und Know-how des Teams, Effektgröße und p-Wert des Ergebnisses. Keine dieser Variablen konnte den Replikationserfolg alleine erklären, obwohl die empfundene Bedeutung des Effekts wie auch die Expertise der Original- oder Replikationsteams offenbar keinen Einfluss auf die Replikationsrate hatten.
Stattdessen wiesen die p-Werte der Originaleffekte samt deren Größen eher auf einen Replikationserfolg hin. Ergebnisse mit p-Werten knapp unter 0,05 konnten nicht gut repliziert werden; solche mit p-Werten zwischen 0,04 und 0,05 hatten eine magere Erfolgsquote von 18 Prozent (zwei von 11 Resultaten waren erneut signifikant); diejenigen mit p-Werten zwischen 0,02 und 0,04 kamen zusammen auf 26 Prozent (sechs von 23). Im Gegensatz dazu wurden von 32 Studien mit einem p-Wert &llt; 0,001 zwanzig erfolgreich repliziert (wiederum definiert als signifikanter p-Wert bei der Replikation) – macht 63 Prozent. Diese Studie liefert damit empirische Daten für die Forderung der Statistiker, nicht blind einem p-Wert von 0,05 zu vertrauen.
(Natürlich sollten wir grundsätzlich nicht von irgendeinem beliebigen p-Wert abhängig sein, überhaupt sollten wir Nullhypothesen-Signifikanztests am besten ganz vergessen und stattdessen Bayes’sche Statistik verwenden – aber bis das ganze Feld dort ankommt, können wir ruhig damit beginnen, ein bisschen strikter zu sein.)
Was sagen diese Zahlen über neurowissenschaftliche Forschung mit menschlichen Probanden? Zunächst sollte man im Auge behalten, dass die kognitive Neurowissenschaft solche kognitionswissenschaftlichen Studien wie oben erwähnt durch bildgebende Verfahren wie etwa die funktionelle Magnetresonanztomographie (fMRT) erweitert. Grundsätzlich sind zwar ähnliche Replikationsraten zu erwarten, insbesondere zwei Faktoren können diese hier allerdings noch weiter nach unten ziehen: niedrigere Probengrößen und weitverbreitete Missverständnisse über die multiple Testkorrektur bei fMRT.
Zum Thema niedrigere Probengrößen können wir uns kurz fassen: Die oben erwähnte Studie über präklinisch-neurowissenschaftliche Arbeiten untersuchte überdies auch Neuroimaging-Projekte mit menschlichen Probanden – und berichtet eine mittlere statistische Power von lediglich acht Prozent (4). Das ist absurd niedrig und ist wahrscheinlich den hohen Investitionen an Zeit und Kosten selbst bei kleinen fMRT-Studien geschuldet. Schlimmer aber ist, dass einige offenbar nicht verstehen, dass man mit einer regulären fMRT-Analyse leicht 200.000 Voxel testen kann. Und man muss dabei nicht einmal 200.000 Testentscheidungen korrigieren– zum Beispiel indem man Alpha durch 200.000 dividiert –, da diese Voxel ja miteinander korreliert sind...
fMRT-Datenpunkte sind meist geglättet, um Ausreißer loszuwerden und „wahre“ Aktivität zu verstärken. Dazu werden die Voxel-Werte jeweils durch den Mittelwert aller Voxel ersetzt, die in einer Kugel mit bestimmtem Radius um ihn herum liegen. Aber auch nach dieser Glättung kann man davon ausgehen, dass es unabhängige Elemente in den Gehirndaten gibt, die man als Resolution Elements (Resel) bezeichnet und deren Anzahl von der durchschnittlichen Glättung der Daten abhängt. Diese unabhängigen Elemente kann man verwenden, um multiple Testprobleme zu beheben – wobei hierzu auch andere Verfahren vorgeschlagen und geprüft wurden (8).
Allerdings wenden einer Schätzung zufolge nur 60 Prozent aller fMRT-Arbeiten überhaupt eine Form der multiplen Testkorrektur (9) an, wovon wiederum ein Drittel diese nicht weiter spezifiziert. Und selbst wo eine multiple Testkorrektur korrekt eingesetzt wurde, landet man im besten Fall wieder nur beim 0,05-Niveau – was ja, wie gesagt, eigentlich eine sehr milde Schwelle ist. Als Fazit heißt das, in fMRT-Projekten werden bereits bestehende statistische Fehler noch verstärkt – und allzu oft nicht wirklich verstanden.
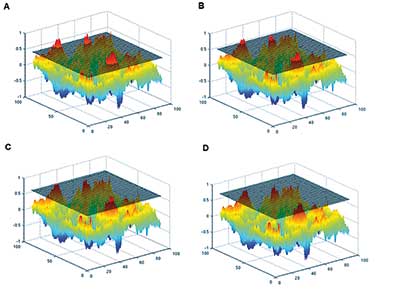
Wenn man nun noch dazu nimmt, dass man Aktivität, funktionelle Konnektivität, effektive Konnektivität sowie neuerdings noch weitere Parameter analysieren kann, und dass man zudem auf einen Test auf Gruppenebene mehrere Post-hoc-Kontraste anwenden kann (um am Ende den zu nehmen, bei dem man etwas findet) – dann wird das Problem unvermeidlich noch größer. Dass unkorrigierte Schwellenwerte dabei mehrere große Cluster hervorbringen können, die völlig beliebig wie in einem Gaußschen Zufallsfeld auftauchen, scheint einigen nicht bewusst zu sein (Abb 2). Zudem können p-Werte pro Voxel durchaus beeindruckend aussehen, wenn man die schiere Menge der Voxel vergisst.
Ein bis zwei Jahre grundlegende, aufbauende und spezifische fMRT-Statistik wären vielleicht ein guter Start für Gruppen, die erstmals eine fMRT-Studie durchführen wollen. Andererseits können manchmal auch erfahrene Gruppen nicht der Versuchung widerstehen, die Schwellen zu senken, nur um ein schönes Bild für eine großartige Geschichte zu haben. Die fMRT hat deshalb zuletzt viel Kritik von Neurowissenschaftlern und sogar von Journalisten einstecken müssen, die nicht mit der Technik vertraut sind. Dabei ist nichts falsch mit der Technik an sich, und es existieren zudem sehr ordentliche Verfahren zur statistischen Korrektur – sie werden nur einfach nicht angewendet. Das Hauptproblem der fMRT sind folglich deren Nutzer, die allzu oft nicht wahrhaben wollen, dass sie auf statistische Karten schauen – und nicht direkt auf Aktivitätskarten.
fMRT-Studien sind zwar nicht die einzigen, in denen statistische Fehler lauern, allerdings können hier kleine statistische Missverständnisse unverhältnismäßig große Effekte verursachen. Immerhin hat inzwischen jedoch vor allem die multiple Testkorrektur einige Aufmerksamkeit bekommen und wird innerhalb der Neuroimaging-Gemeinde offen diskutiert; in anderen Disziplinen, in denen multiple Tests durchgeführt werden – beispielsweise präklinische Arbeiten, die mit mehreren Verhaltensexperimenten auf Unterschiede zwischen Testgruppen testen –, ist dieses Problem jedoch womöglich noch nicht sichtbar genug. Zudem begegnet man häufig auch anderen methodischen und statistischen Fehlern in Studien, die einfache oder „klassische“ Techniken verwenden. Zum Beispiel offenbarte eine aktuelle Analyse, dass die Hälfte aller in High-Impact-Zeitschriften veröffentlichten Interventionsstudien versäumt hatte, die richtigen statistischen Tests durchzuführen – was in einigen Fällen zu ernsthaften Fehldarstellungen der Daten führte (10).
Fest steht, dass in Biologie und Medizin die methodische und statistische Ausbildung in der Doktorandenphase deutlich mehr Aufmerksamkeit bekommen muss – angefangen bei der klassischen Deskriptiven und Inferenzstatistik bis hin zu einer Einführung in die Bayes-Statistik. Die meisten Originalarbeiten in den Neurowissenschaften setzen irgendeine Form von Statistik ein, so dass deren Verständnis von entscheidender Bedeutung ist, um die Literatur verstehend zu lesen, beschriebene Effekte adäquat zu bewerten und sich Klarheit über die eigenen Ergebnisse zu verschaffen. Es kann daher nur helfen, Statistik als akademische Kern-Fertigkeit anzusehen, und nicht nur als Soft Skill wie etwa Antragschreiben, Management oder Präsentation.
Dummerweise erfordert das Lernen von Methodik und Statistik, zusätzlich zum Erlernen der experimentellen Techniken des jeweiligen Feldes sowie dem Entwickeln von Arbeitshypothesen, schlichtweg Zeit und kann nicht immer in ein Master-Studium oder die frühe Doktorandenphase eingepasst werden. Jedoch kann eine unzureichende statistische Ausbildung – wie etwa ein zweitägiger Workshop in irgendeinem statistischen Programm, mit dem man Hunderte von bivariaten Korrelationen durchklicken und erzeugen kann, ohne etwa das multiple Testproblem tatsächlich zu verstehen –, das Falsch-Positive-Problem am Ende sogar stärker verschlimmern als gar keine statistische Ausbildung. Denn schließlich ruft man im letzteren Fall in aller Regel einen erfahrenen Statistiker um Hilfe.
Allerdings muss es auch nicht zwingend die beste Lösung sein, das „Problem“ an Statistiker outzusourcen und sich von diesen beispielsweise bei den Power-Analysen helfen zu lassen. Schließlich arbeiten Statistiker in aller Regel nicht im Labor. Folglich können sie um Rat gefragt werden oder nicht, sie können angehört werden oder auch nicht – aber sie können ganz sicher nicht einen PI überstimmen, wenn die betreffenden Ergebnisse zwar allzu schön, aber wahrscheinlich falsch sind.
Alternativ könnte eine direkte statistische Beratung natürlich während des Review-Prozesses einer Zeitschrift stattfinden. Allerdings ist leider unwahrscheinlich, dass Zeitschriften für Dienstleistungen bezahlen, die ansonsten einer der Gutachter oftmals umsonst liefert. Zumal sie diese womöglich dazu zwingen würden, mehr wirklich solide und weniger „spannende“ Ergebnisse zu publizieren.
Wie also können wir letztlich wahre Signale gegenüber dem belanglosen Rauschen in Forschungspublikationen verstärken? Natürlich durch eine bessere Ausbildung und mehr Verständnis in Statistik, durch höhere statistische Power in den Untersuchungen, indem wir zweifelhafte Arbeiten nicht zitieren, indem wir Doktoranden einen t-Test wenigstens einmal von Hand machen lassen, indem wir Konfidenz- und Vertrauensintervalle mit veröffentlichen,... und und und. Allerdings kann es Jahre, wenn nicht Jahrzehnte dauern, bis die Mehrheit endlich den bequemen Weg verlässt, auf dem Wissenschaft innerhalb des derzeitigen Belohnungssystems betrieben wird. Schließlich juckt es ja nicht, wenn man „Lärm“ erzeugt – solange man dafür belohnt wird.
Dabei hat zumindest eine neue Analyse prinzipiell gezeigt, dass es gar nicht schwer sein muss, das derzeitige „Falsch-Positiv“-System zu verändern. Wir müssen einfach nur strikter sein.
Valen Johnson von der Texas A & M University entwickelte einen Weg, klassische p-Wert-Tests (auch als frequentistischer Ansatz bezeichnet, da der Fokus auf der Wahrscheinlichkeit eines gegebenen Testergebnisses liegt) mit Bayes’schen Faktoren zu vergleichen. Dabei stellte er fest, dass ein p-Wert von etwa 0,05 einem Bayes-Faktor zwischen 3 und 5 entspricht (11) – was in der Regel als schwacher Hinweis dafür angesehen wird, dass eine gegebene Hypothese stärker als eine andere gestützt wird. Auch Johnson sieht darin das Hauptproblem dafür, dass man viele unreproduzierbare Ergebnisse erhält – und folgert, dass man es zuerst durch das Anlegen strengerer statistischer Schwellen lösen könnte, wie beispielsweise p < 0,005 oder gar p < 0,001. Solche Schwellen würden viel überzeugendere Beweise für die betreffenden Hypothesen bieten (und würden die Forscher automatisch zwingen, größere Probenmengen zu verwenden).
Ein Jahr, nachdem Johnson seine Berechnungen veröffentlicht hatte, untermauerte die oben erwähnte großangelegte Replikationsstudie seine Analyse mit den ersten empirischen Daten: Die Replikationsraten reichten von 18 Prozent für einen p-Wert knapp unter 0,05 bis zu 63 Prozent für Werte unter 0.001 (7).
Valen Johnson schloss damals: „Es ist wichtig zu beachten, dass diese hohe Rate an Nichtreproduzierbarkeit nicht das Ergebnis von wissenschaftlichem Fehlverhalten, von Publikations- und Schubladen-Bias, oder von fehlerhaftem statistischen Studiendesign ist; vielmehr ist dies schlichtweg die Folge davon, Schwellen zu verwenden, die keine ausreichend starke Evidenz liefern, um einen erwarteten Effekt zu untermauern.“
Zeit also, den Glauben an einen magischen p-Wert von 0,05 zu stoppen. Und Zeit aufzuhören, derjenigen Forschung zu vertrauen, die weiterhin daran glaubt.
Victor Spoormaker ist wissenschaftlicher Mitarbeiter am Max-Planck-Institut für Psychiatrie in München. Seit 2011 ist er Mitglied des Jungen Kollegs der Bayerischen Akademie der Wissenschaften.
Referenzen
- Ioannidis JPA. Why Most Published Research Findings Are False. PLoS Med. 2005;2(8):e124.
- Prinz F, Schlange T, Asadullah K. Believe it or not: how much can we rely on published data on potential drug targets? Nat Rev Drug Discov. 2011;10(9):712.
- Begley CG, Ellis LM. Drug development: Raise standards for preclinical cancer research. Nature. 2012;483(7391):531-3.
- Button KS, Ioannidis JPA, Mokrysz C, Nosek BA, Flint J, Robinson ESJ, et al. Power failure: why small sample size undermines the reliability of neuroscience. Nat Rev Neurosci. 2013;14(5):365-76.
- Fanelli D. “Positive” Results Increase Down the Hierarchy of the Sciences. PLoS ONE. 2010;5(4):e10068.
- Halsey LG, Curran-Everett D, Vowler SL, Drummond GB. The fickle P value generates irreproducible results. Nat Meth. 2015;12(3):179-85.
- Open Science Collaboration. Estimating the reproducibility of psychological science. Science. 2015;349(6251).
- Nichols T, Hayasaka S. Controlling the familywise error rate in functional neuroimaging: a comparative review. Statistical Methods in Medical Research. 2003;12(5):419-46.
- Carp J. The secret lives of experiments: Methods reporting in the fMRI literature. NeuroImage. 2012;63(1):289-300.
- Nieuwenhuis S, Forstmann BU, Wagenmakers E-J. Erroneous analyses of interactions in neuroscience: a problem of significance. Nat Neurosci. 2011;14(9):1105-7.
- Johnson VE. Revised standards for statistical evidence. Proc Nat Acad Sci USA. 2013;110(48):19313-7.
Letzte Änderungen: 12.07.2016